上周我们讲述了部署Cloudera EDH的考虑之二,即组成Cloudera 企业版部署的各种服务和角色。上周介绍的是分析型数据库。本周我们讲下操作性数据库。
操作数据库由以下一组核心高级组件支持:
上周关于分析型数据库的内容中对核心组件已经做了介绍,其它支持分析型数据库的组件也支持操作型数据库。
HBase,Kudu和Solr为各种操作用例提供各种低延迟插入、更新、删除和提取存储选项。Solr由Hue进一步增强,这就是为什么我们在集群中包含Hue,以便快速提供创建搜索仪表板的方式。
Spark在这里不仅用于强大的处理功能,还用于SQL和流式处理以快速将数据带入该群集。
最后,通过流式传输,我们将包含一个Kafka专用集群,它通常是许多流式架构中的关键组件,特别是来自上游Spark Streaming用户将数据放在HBase,Kudu或Solr上。
可以按照下图所示分配服务:
操作型数据库特定组件
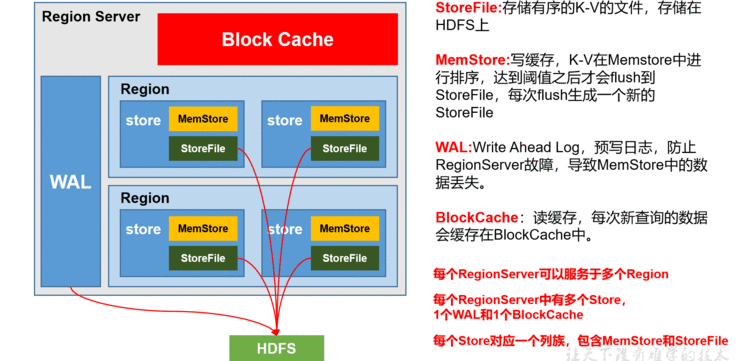
HBase:跨主节点部署一组HBase主控(HMaster)。RegionServers部署在所有工作节点上。 高可用性可通过ZooKeeper来确定哪些HMaster请求应该被指向。
Cloudera Search:Cloudera 搜索由几个组件组成,包括部署在所有worker节点上的Solr。 Hue是Cloudera搜索提供搜索仪表板功能的另一个组件。如果Solr服务器发生故障,Solr集合应复制到多个Solr服务器,以实现完全高可用性。
Kudu:请参阅上周分析型数据库中的内容,Kudu服务角色布局与此相同。
Spark和Spark2:请参阅上周分析型数据库中的内容,Spark服务角色布局与此相同。
Navigator:Navigator 加密和Key Trustee已在上周分析型数据库中的内容中进行了介绍。
Kafka:Kafka应该驻留在自己的群集中,尽管它可能由管理操作型数据库群集的同一个Cloudera Manager来管理。在前几个Kafka Broker中部署了一个单独的ZooKeeper集群以及一对Sentry角色。Kafka Broker中也可放Flume服务,使用Flume Source从上游来源获取数据,通过Kafka sink或Kafka channel将事件提供到Kafka集群,这些都需要Flume服务。
其余的服务在平台上都是通用的,在上周分析型数据库部分都已经介绍,可点击下方链接回顾上期内容。
微博 | 部署Cloudera EDH集群考虑之二:服务和角色(分析型数据库)
微博 | 部署Cloudera EDH集群考虑之一:架构
更多资讯,请点击“阅读原文”














 京公网安备 11010802041100号
京公网安备 11010802041100号